직원 동료의 이야기를 듣고 함께 참가하게 된 POSCO AI Chanllenge 에 좋은
성적으로 입상을 하게 되어 본선에서 발표를 준비해야 하는 상황까지 오게
되었다.
참여하게 된 과제는 주어진 데이터를 기반으로 과거의 너울성 파도를
예측하는 과제로써, 3차 최종 결과 제출본 기준으로 2등을 하게 되었으며
상위 3팀이 본선을 진출하고 발표는 내일이다. 발표를 준비하는 겸, 지금까지
수행한 과제를 정리도 할겸 글을 정리해 보고자 한다.
과제의 목표
필자는 대회 설명회 때 참석하지 못하여 생생함이 덜 하지만
설명회의 이야기로는 너울성 파도를 사전에 예측하여 선박의 출항 여부에
대해 의사결정에 도움을 받고
이어서 경제적, 인명적 손실을 최소화하기 위함이라고 전해 들었다.
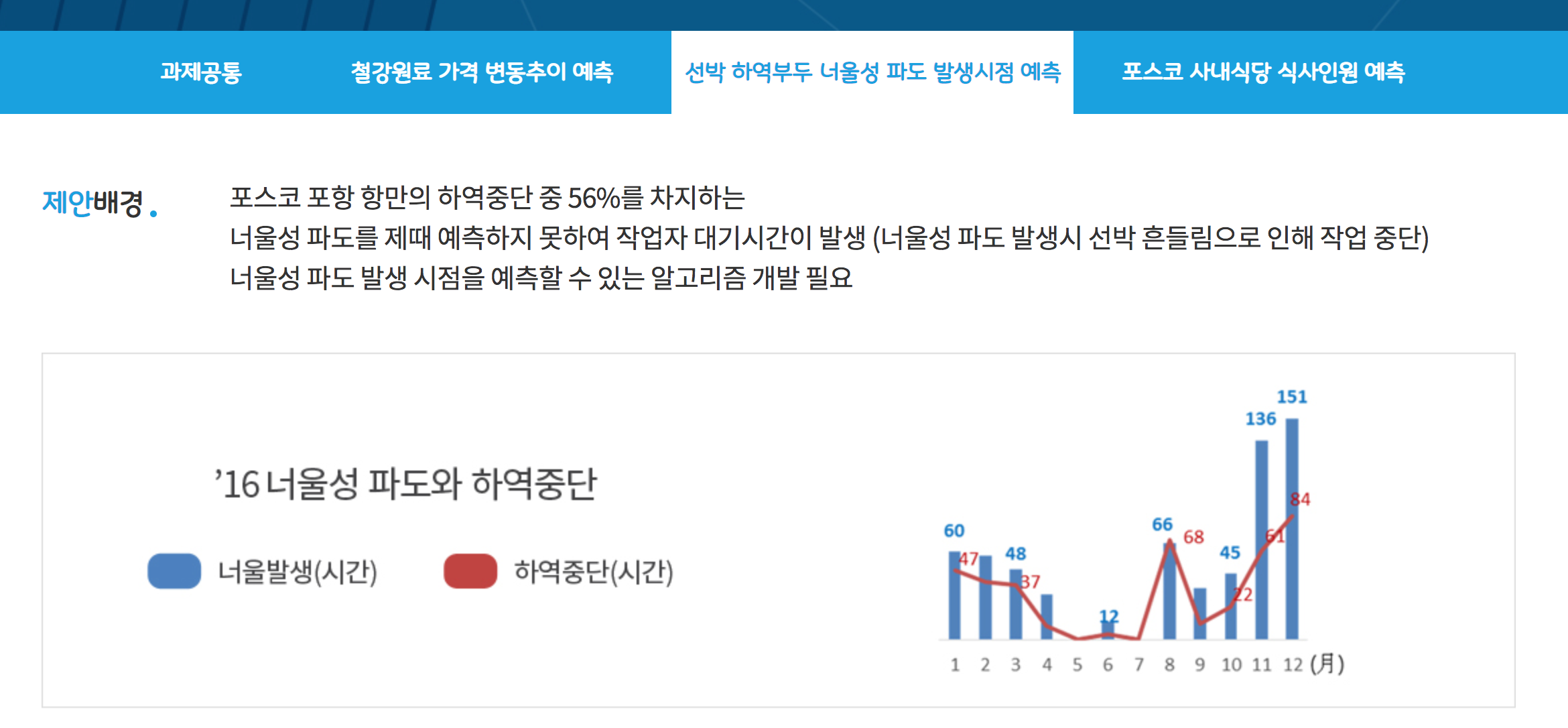
POSCO 사의 입장으로써 이전부터 고민이 많은 이슈라 생각이 들었고, 그로 인한 계기로 본 과제를 기획한 것으로 생각된다.
데이터 현황과 전처리 수행과정
공급받은 데이터는 포스코 본사에 있는 포항 항구 근처에서 수집한 파고,
및 해수온도, 풍향등의 데이터이며 수집 지점은 월포, 구룡포 두 지점에 대한
약 3년치 자료이다.
그리고 과거 3년에 너울이 발생했는지의 여부를 시간 단위로 판단할 수 있는
정답지 데이터 (Training dataset), 그리고 과제의 미션으로 예측을 해내야
하는 시점이 언제인지를 알려주는 시험지 데이터(Predict dataset)로
구성되어 있다고 볼 수 있다.
## # A tibble: 2,247 x 11
## loc date mean_temp max_temp min_temp mean_signi_wh mean_wh
## <int> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 22453 2014-01-01 13.7 13.8 13.6 0.6 0.4
## 2 22453 2014-01-02 14 14.3 13.6 0.7 0.5
## 3 22453 2014-01-03 14.4 14.9 14.1 0.6 0.4
## 4 22453 2014-01-04 14.5 14.8 13.9 1.3 0.8
## 5 22453 2014-01-05 14.4 14.6 14.3 1.5 0.9
## 6 22453 2014-01-06 14.1 14.3 14 1.1 0.7
## 7 22453 2014-01-07 13.9 14.3 13.7 0.7 0.4
## 8 22453 2014-01-08 13.8 14.1 13.4 0.4 0.3
## 9 22453 2014-01-09 13.8 14.3 13.2 1.4 0.8
## 10 22453 2014-01-10 13.5 13.9 13.1 1 0.6
## # ... with 2,237 more rows, and 4 more variables: max_signi_wh <dbl>,
## # max_wh <dbl>, mean_cycle <dbl>, max_cycle <dbl>제공받은 항구별 수집 정보들의 rawdata 의 샘플
## # A tibble: 1,231 x 5
## date swell start_time end_time testset
## <date> <dbl> <time> <time> <int>
## 1 2014-01-04 NA 15:00 19:00 0
## 2 2014-01-04 NA 19:00 07:00 0
## 3 2014-01-05 NA 07:00 10:00 0
## 4 2014-01-05 3 10:00 13:00 0
## 5 2014-01-08 NA 10:00 19:00 0
## 6 2014-01-09 4.5 14:30 19:00 0
## 7 2014-01-09 12 19:00 07:00 0
## 8 2014-01-10 3 07:00 10:00 0
## 9 2014-01-10 2 10:00 13:00 0
## 10 2014-01-21 1.5 00:30 02:00 0
## # ... with 1,221 more rows제공받은 정답지 데이터와 시험지 데이터의 rawdata 샘플
제공받은 데이터 외의 다른 데이터를 이용해도 된다는 주최측의 안내를
받고 자체적으로 추가 수집한 데이터도 있었으며
그 데이터는 포항 앞바다의 부이1로 부터 수집된
데이터이다.2
## # A tibble: 8,541 x 14
## location date wind_speed wind_direction GUST local_air_press~ humidity
## <int> <chr> <dbl> <int> <dbl> <dbl> <int>
## 1 22106 2014~ 8.2 259 11.1 1008. 44
## 2 22106 2014~ 10.6 287 15.1 1009. 43
## 3 22106 2014~ 11.7 287 14.9 1009. 42
## 4 22106 2014~ 11.5 302 16.2 1010. 46
## 5 22106 2014~ 11.8 284 16.4 1010. 50
## 6 22106 2014~ 9.1 294 12.4 1010. 48
## 7 22106 2014~ 7.3 293 11.7 1012. 43
## 8 22106 2014~ 6.4 298 8.5 1012. 37
## 9 22106 2014~ 5 296 8.1 1013. 35
## 10 22106 2014~ 6.3 270 9.5 1014. 35
## # ... with 8,531 more rows, and 7 more variables: temperature <dbl>,
## # water_temperature <dbl>, max_wave_height <dbl>,
## # mean_wave_height <dbl>, avg_wave_height <dbl>, wave_accurance <dbl>,
## # wave_direction <int>추가로 수집한 부이데이터의 rawdata 샘플
이러한 데이터들을 충분히 EDA 한 후 머신러닝이나 딥러닝의 프레임워크
툴들이 학습하기 용이하도록 학습데이터 마트로 만들기 위한 단계를
거쳤다.
너울성 파도의 여부를 swell 이란 필드명으로 각 시간별
상황데이터(파고, 풍향, 풍속, 수온 등등의 설명변수집합)에 맵핑하는
전처리를 수행하였다.
그 결과는 아래와 같다.
## # A tibble: 6,909 x 15
## date time swell wind_speed wind_direction GUST air_pressure humidity
## <chr> <int> <int> <dbl> <int> <dbl> <dbl> <int>
## 1 2014~ 0 1 11 302 14 1026. 47
## 2 2014~ 1 1 11.1 315 16.1 1027. 45
## 3 2014~ 10 1 9.9 320 14.1 1030. 54
## 4 2014~ 11 1 9.8 306 13 1030. 54
## 5 2014~ 12 1 8.7 324 13.6 1030 49
## 6 2014~ 2 1 11.7 314 15.4 1027. 46
## 7 2014~ 3 1 12.4 324 16.8 1027. 49
## 8 2014~ 4 1 12.5 320 17.8 1028. 45
## 9 2014~ 5 1 13.7 311 17.5 1029. 49
## 10 2014~ 6 1 14.2 320 17.5 1029. 50
## # ... with 6,899 more rows, and 7 more variables: temperature <dbl>,
## # water_temperature <dbl>, max_wave_height <dbl>,
## # mean_wave_height <dbl>, avg_wave_height <dbl>, wave_accurance <dbl>,
## # wave_direction <int>정답지가 존재하는 시점을 date, time 두
필드로 시점의 정보를 부여하고
그 시점의 너울성 파도 여부를 구분하는 swell 을 맵핑하였으며
(너울성 파도가 일어난 경우 1, 그렇지 않은경우 0)
EDA 를 통해 선별한 12개의 설명변수
wind_speed: 풍속wind_direction: 풍향GUST: 돌풍의 정도air_pressure: 기압humidity: 주변습도temperature: 주변온도water_temperature: 수온max_wave_height: 파고최대높이mean_wave_height: 파고평균높이avg_wave_height: 파고유의높이wave_accurance: 파고주기wave_direction: 파도방향
를 같이 맵핑하였다.
참고로 결측값에 대한 이슈도 있었는데
맵핑과정에서 그 시간시점에 해당 하는 데이터가 존재하지 않아 결측이
일어나는 경우가 바로 그것이었다.
결측행을 제외하는 것은 데이터의 손실이 너무 크다고 판단하였고 따라서
결측을 대치하는 방법을 고려했다.
대부분 LOCF(Last Observation Carried Forward) 방법으로 가장 최근값을
상속시키는 결측대치법을 이용하였고, LOCF 결측대치가 타당하지 않다고
판단되는 풍속(wind_direction)의 경우 중앙값 대치를 고려하여
적용했다.
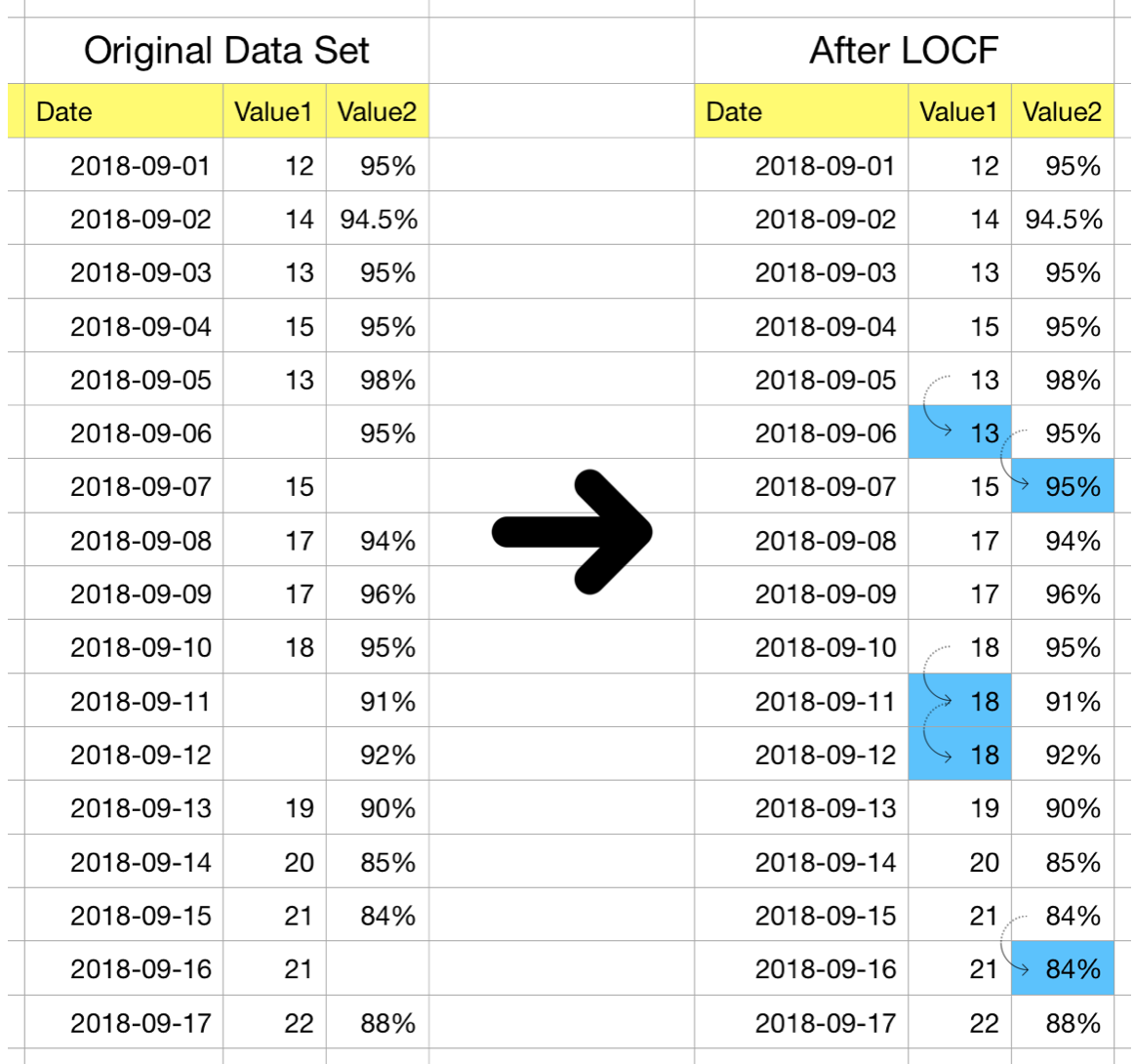
LOCF(Last Observation Carried Forward) 를 통해 결측이 대치되는 방법에 대한 그림
너울성 파도 예측 모형 구현
본 과제의 명칭에 걸맞게 AI 기술을 이용하여 너울성 파도를 예측하고자
예측 모형을 구현하고 Validation set 을 통해 모형을 평가하였다.
머신러닝 기법과 그중에서도 딥러닝 기법들을 다양하게 테스트 해보고
예측성능이 높게 평가된 것을 선별하여 1,2,3차에 걸쳐 제출하게 되었다.
1,2,3차 때는 각 차수별로 대략 2주간의 시간이 주어졌다고 볼 수
있는데
각 차수별 아래와 같은 목표로 진행하였다.
1차때는 딥러닝 모델을 구현하기 전 손쉽게 적용해 볼 수 있는 전통적인 머신러닝 알고리즘들을 이용하여 Warming up 을 해보는 단계로 계획하여 테스트 해 보았다.
2차때는 1차때 선별된 머신러닝 알고리즘의 모형보다 예측성능이 더 높은 딥러닝 기반의 모형을 구현하는 것을 목표로 잡고 딥러닝 모형을 구현하였다.
3차때는 역시 2차때 선별된 딥러닝 알고리즘보다 더 높은 예측성능을 보이는 모델을 찾기 위해 더 다른 관점의 고민들을 해보는 기간으로 잡았다.
그 결과
- 1차 : Weighted Subspace Random Forest 알고리즘 모형
- 2차 : Artificial Neural Network(ANN) 모형
- 3차 : Flexible Discriminant Analysis(FDA) 모형
3개의 모형을 구현하였고, 이를 통한 예측값을 제출하게 되었다.
모형 평가
모형의 예측성능을 평가하기 전
무엇을 객관적인 목표로 잡고 각 3개의 모형이 선별되었는지 선발 기준에
대한 설명을 사전에 할 필요가 있을 것 같다.
본 과제는 Binary Classification 문제이고, 특히 너울성 파도가 일어난
이벤트의 당시상황이 중요하므로 “너울성파도가 일어난” 시점에 대해서,
모형이 “너울성 파도가 일어남” 이라고 예측하는 것이 더 중요했다.
더 중요한 이유는 너울성 파도는 드물게 일어나며, 평시 상황은 너울성파도가
일어나지 않는 상황이어서 “너울성 파도가 일어나지 않은” 시점에 대해서,
모형이 “너울성 파도를 일어나지 않음”으로 예측하는 것은 조금 덜
중요하다고 볼 수 있다.
이런 특성 때문에 과제 평가 정책을 상황별로 다르게 스코어링 하였었고, 그
공식은 아래와 같다.
- 너울성파도가 일어난 시점에 대해서 모형이 너울성 파도가 일어났다고
예측 : 2점 증가
- 너울성파도가 일어난 시점에 대해서 모형이 너울성 파도가 일어나지
않았다고 예측 : 2점 차감
- 너울성 파도가 일어나지 않은 시점에 대해서 모형이 너울성 파도를
일어나지 않았다고 예측 : 1점 증가
- 너울성 파도가 일어나지 않은 시점에 대해서 모형이 너울성 파도가 일어났다고 예측 : 1점 차감
이 공식에 의해서 우리가 정한 Validation set 상에서의 최대치 점수는 1943점이었고 각 차수별 모형은 아래의 예측성능 점수를 매길 수 있었다.
- 1차 Weighted Subspace Random Forest 알고리즘 모형 : 1471점
- 2차 Artificial Neural Network(ANN) 모형 : 1507점
- 3차 Flexible Discriminant Analysis(FDA) 모형 : 1545점
각 차수별 연구노트 정리
각 차수 별로 각각 아래의 연구를 통해 모형을 구현하고 예측셋 시험지를 풀었다.
1차
머신러닝 알고리즘을 이용한 워밍업 단계라고 설명했는데
실제론 1차때 테스트해 본 케이스들이 정말로 많았다.
실험 알고리즘 케이스는 R의 caret 패키지의 머신러닝 프레임워크의 도움을
얻어 대표적으로 아래의 테스트를 해보았다.
- Partial Least Squares
- Generalized Linear Model
- Linear Discriminant Analysis
- ROC-Based Classifier
- k-Nearest Neighbors # Test 제외
- CART 5.0(Classification and Regression Tree)
- Weighted Subspace Random Forest
제시된 7개 머신러닝 알고리즘은 분류문제에 특화된 알고리즘으로써 본
데이터에 대해 성능을 기대하였던 알고리즘이다.
80%의 과거데이터를 Training set 으로 이용하기 위하여 파티션을 취했고,
이를 재료로 학습을 통해 모형을 구축하였다.
k Fold 교차검증으로3 각 알고리즘별 튜닝파라미터를
선정하였고, 파티션에 남은 20% 최근 데이터를 통해 예측성능을 확인해
보았다.
7개 알고리즘 모형 중 Weighted Subspace Random Forest 알고리즘을 이용한 모형이 1471점으로 예측성능이 가장 높아 선정하게 되었다.
2차
1차때 선정된 Weighted Subspace Random Forest 알고리즘 모형보다 더
높은 예측성능을 내는 딥러닝 구현을 목표로 인공신경망(ANN)에 해당 하는
기법들을 테스트했다.
순환신경망(RNN), 심층신경망(DNN) 등을 테스트 하였고, 하이퍼 파라미터들에
대한 실험케이스들을 여러 개로 나누어 1차때의 예측성능 보다 높은 모형을
만들기 위해 노력했다.
그 결과 1507점을 내는 모형을 찾게 되었다.
3차
3차때는 전반적인 데이터의 현황에 대한 검토를 면밀하게 하고 넘어가고자
했다.
과제 전부터 한가지 집혔던 것이
전처리가 완료된 학습데이터 마트에 대한 EDA 후 확인되었던 이슈지만
너울성 파도의 발생 이벤트가 매우 소수이어서, 이 소수인 클래스의 학습력이
상대적으로 부족할 것이라고 우려했었다. 즉 Class imbalance problem 의
문제를 먼저 풀고 모델링에 들어가면 더 유리할 것이라고 생각했었다.
이 부분을 해결하기 위해 너울성 파도가 일어난 데이터(swell =
1)를 늘리면서 너울성 파도가 일어나지 않은 데이터(swell =
0)와 균형이 맞도록 Random Over Smapling 을 통해 학습셋을 기존
6,000여건에서 20,000여건으로 늘려 재구성 해 보았다.[^구현 방법은 R의
ROSE package를 이용했다]
이후 재구성된 학습셋을 기준으로 이전에 시도했던 알고리즘들을 다시 돌려보고, 추가로
- Radial Basis Function Network
- Flexible Discriminant Analysis
두개의 머신러닝 알고리즘을 더 고려하여 테스트 해보니, 이전보다 더 높은 예측성능을 내는 모형이 나타났고 그 결과 Flexible Discriminant Analysis 모형이 1545점 으로 지금까지 수행한 모형의 예측성능 중 가장 높게 나온 모델을 만들었다.
모델링 이전 신경 썼던 부분
인공지능 모형이 오버피팅이 되는 것을 사전에 막고, 제한된 학습셋을
통해 우리가 알지 못하는 실제 Test set 에 대해 잘 예측해내는 모형을
만들기 위해선 데이터에 대한 다각도의 이해와 인공지능을 구현하기 위한
머신러닝 & 딥러닝 알고리즘에 대한 어느 정도 이론적인 이해도가
필요했다.
특히 차원의 저주로 인하여 타겟을(너울성파도) 예측하는데 더 많은 데이터를
필요로 하는 것을 막기 위하여 다중 공산성을 고려해 상관도가 높은
설명변수의 조합을 줄여보는 시도도 했고,
시계열적인 파생변수가 타겟과 유의미한 연관 관계가 있는지도 데이터
시각화를 통해 살펴보는 등
EDA 를 꽤 정성들여 해 본것이 인상깊었다. (사실 EDA 는 하면 할수록 욕심이
생겨 끝도 없이 해 볼 수 있는 과정이라 생각하는데.. 제한시간이 있었기에
어느 단계에서 멈출수 있었다는 건 함정..)
이는 Feature engineering 측면에서 다양한 실험케이스를 만들어 분석을
풍부하게 해 볼 수 있는 요인으로 작용했지만
본 과제의 결론은 Full model(가용 가능한 설명변수를 모두 이용하는 모델)이
채택이 되었었다.
해상의 기상 상황을 관측하는 장비를 의미한다↩︎
출처는 기상청 국가 기후 데이터 센터이다↩︎
상황에 따라 K를 8, 10 등으로 바꾸어서 하기도 해서 그냥 K라 표기한다↩︎