
개요
R에서 범주형 변수를 다룰 때 factor 형을 이용한다.
범주형 자료는 연속형 자료와는 다르게 그 자체의 고유한 의미를 가진다는
특성때문에 정성적인 관리가 필요한 편이다.
애초에 많은 관심을 필요로 하고 있다고 볼 수 있다.
이러한 이유로 범주형 자료를 접근하고 핸들링하는 많은 함수들이 R에
존재한다.
최근에는 factors 의 알파벳 순서를 교묘히(?) 바꾸어 네이밍한 forcats
package 가 CRAN 에 등록되었는데, 고양이를 위한 패키지가
아니라 factor형 핸들링을 위한 함수들이 제공되는 패키지이다.
The goal of the forcats package is to provide a suite of useful tools that solve common problems with factors.
- forcats package 의 README.md 중에서
패키지 설치
CRAN 에 등록되어 있으므로
install.packages("forcats")로 설치할 수 있다.
major 버전은 아직 0 이므로1 지속적으로 개선될
가능성이 높다.
개발버전을 사용하고 싶다면 Github 를 통해 패키지를 설치해도 되겠다.
# Or the the development version from GitHub:
devtools::install_github("tidyverse/forcats")Getting started
forcats package 의 함수들은 “fct_” 로 시작한다.
이후의 단어가 함수쓰임의 의미를 담고 있다.
| 함수명칭 | 내용 |
|---|---|
| fct_anon | Anonymise factor levels |
| fct_c | Concatenate factors, unioning levels. |
| fct_collapse | Collapse factors into groups. |
| fct_count | Count entries in a factor |
| fct_drop | Drop unnused levels |
| fct_expand | Add additional levels to a factor |
| fct_explicit_na | Make missing values explicit |
| fct_infreq | Reorders levels in order of first appearance or frequency. |
| fct_inorder | Reorders levels in order of first appearance or frequency. |
| fct_lump | Lump together least/most common levels into “other”. |
| fct_recode | Change the levels of a factor |
| fct_relevel | Change the order of levels in a factor |
| fct_reorder | Reorder the levels of a function according to another variable |
| fct_reorder2 | Reorder the levels of a function according to another variable |
| fct_rev | Reverse the levels of a factor |
| fct_shift | Shift the order of levels of a factor |
| fct_shuffle | Randomly permute the levels of a factor |
| fct_unify | Unify the levels in a list of factors |
| fct_unique | Unique values of a factor |
접두사 “fct_” 가 코딩할 때 불편할 수도 있겠다 싶지만, 오히려 “fct_” 가 있음으로 변수형자료를 핸들링하는 것임을 정확하게 인지할 수 있는 tag같은 역할을 하는 것 같기도 해서 나는 개인적으로 좋다. 2
여하튼 이 함수들 중 자주 사용하는 것을 몇 개 언급해보고자 한다.
fct_recode()
factor 형 자료를 다룰 때 가장 번거로운 것 중 하나는 요인의 성격을 보존한 채 오직 명칭만 변경하는 과정이다.
예를 들면
ex <- factor(c("L", "M", "small", "small", "L", "M", "L"),
levels = c("small", "M", "L"))
ex## [1] L M small small L M L
## Levels: small M L위와 같은 ex factor 형 자료의 요인들은 “small”, “M”, “L”
3개가 있다.
흠.. 그런데 요인의 명칭이 뭔가 맘에 들지 않는다(고 가정하자).
특히 “small” 을 “S” 로 바꾸기만 하면 좋을 것 같아
levels(ex)[levels(ex) == "small"] <- "S"와 같은 코딩을 필자 이전까지 해왔었다.
전통적인 방식이지만 어찌 보면 무식하고 조악한 코딩일 수도 있겠다.
forcats package 에선 위의 예시처럼 요인명칭을 변경할 일이 있을
때
수준들의 위치를 인덱싱해 수동적으로 바꾸는 방법 대신
fct_recode() 라는 함수를 통해 바꿀 수 있는 방법을
제공한다.
fct_recode(ex, S = "small")## [1] L M S S L M L
## Levels: S M L잠깐 딴 길로 세보자.
함수로써 제공한다는 것은 의외로 큰 의미가 있는데
R을 제대로 사용하시는 분들이라면 이 의미는 가볍게 알 것이다.
fct_recode() 함수 이외의 forcats package 내에 함수들은 모두
혼자서 외롭게 활용될 일은 거의 없을 것이다.
아래 코드는 dplyr package 와 함께 fct_recode() 함수를 좀 더
실용적으로 사용해 본 예라고 할 수 있겠다. (참고로 gss_cat
는 forcats 패키지에 내장되어있는 데이터셋이다)
# Origin
gss_cat %>% count(partyid)## # A tibble: 10 x 2
## partyid n
## <fctr> <int>
## 1 No answer 154
## 2 Don't know 1
## 3 Other party 393
## 4 Strong republican 2314
## 5 Not str republican 3032
## 6 Ind,near rep 1791
## 7 Independent 4119
## 8 Ind,near dem 2499
## 9 Not str democrat 3690
## 10 Strong democrat 3490# Change level values
gss_cat %>%
mutate(partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat"
)) %>%
count(partyid)## # A tibble: 10 x 2
## partyid n
## <fctr> <int>
## 1 No answer 154
## 2 Don't know 1
## 3 Other party 393
## 4 Republican, strong 2314
## 5 Republican, weak 3032
## 6 Independent, near rep 1791
## 7 Independent 4119
## 8 Independent, near dem 2499
## 9 Democrat, weak 3690
## 10 Democrat, strong 3490fct_lump()
lump 영단어의 뜻은 “덩어리”, “한 무더기” 정도이다.
파편들을 모아 한 덩어리로 만들어 주는 fct_lump(), 곰곰이
생각해 보면 “파편들을 모아 한 덩어리로 만드는” 일은 꽤 많다.
이런 예제를 생각하면 바로 이해가 될 것 같다.
d2 <- gss_cat %>%
count(partyid) %>%
arrange(n)
pie(d2$n, d2$partyid)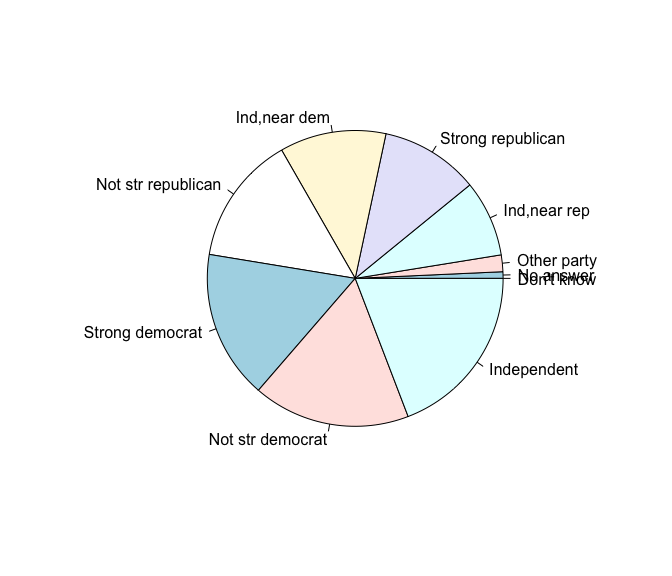
응답 비율이 매우 낮은 요인들은 “Don’t know”, “No answer”, “Other
party” 등이 있다.
응답 비율이 너무 낮아서 pie chart 에 잘 보이지 않고 겹쳐저 있다.
그리고 응답 비율이 너무 낮은것은 때로는 의미가 없어 “etc” 와 같은
기타항목으로 처리하곤 하는데
이때 “Don’t know”, “No answer”, “Other party” 에 해당되는 요인들을 기타
항목으로 덩어리를 만들기 위해선 뜻밖에 많은 고민이 필요할 수 있다.
우리가 알고 있는 fct_recode() 함수로 이를 해결할 수도
있다.
d2 <- gss_cat %>%
mutate(partyid = fct_recode(partyid,
"etc" = "Don't know",
"etc" = "No answer",
"etc" = "Other party"
)) %>%
count(partyid) %>%
arrange(n)
pie(d2$n, d2$partyid)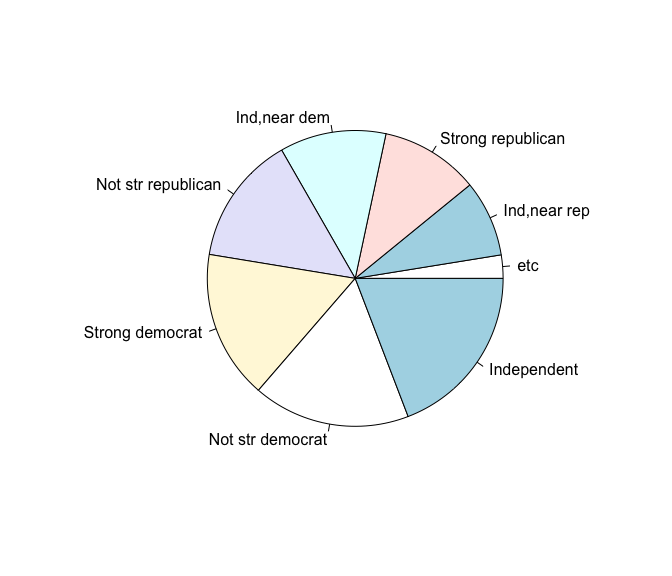
응답 비율이 낮은 요인들을 “etc” 라는 명칭으로 바꾸면 된다.
음.. 그런데 좋은 해결책으로도 보일 수 있겠지만 이방법은 비효율적인
문제가 역시 있다.
일단 “Don’t know”, “No answer”, “Other party” 3개의 요인이 응답 비율이
낮은 것임을 사후적으로 인지해야 하고,
이후 “etc” 라는 명칭으로 바꾸는 것은 뭔가 일을 2번하는 느낌을 받을 수
있다.
fct_lump() 함수는 이처럼 “etc” 라는 덩어리를 아주
간단하게 만들어 준다.
d2 <- gss_cat %>%
mutate(partyid = fct_lump(partyid, n = 7, other_level = "etc")) %>%
count(partyid) %>%
arrange(n)
pie(d2$n, d2$partyid)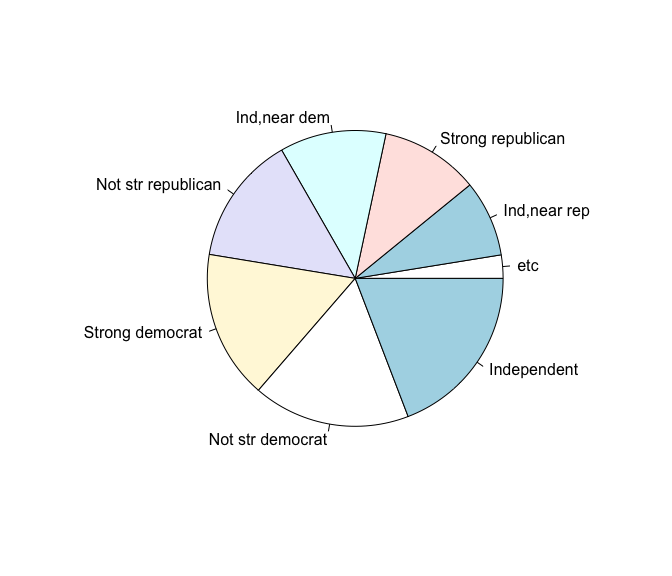
fct_lump(partyid, n = 7, other_level = "etc") 를
살펴보면 n 인자를 7로 설정하여 7개의 주항목 요인 외에는
“etc” 라는 명칭으로 자동으로 바꿔준다.
따라서 pie chart를 보면 소수의견인 “Don’t know”, “No answer”, “Other
party” 요인들이 “etc” 로 통합된 것을 확인할 수 있다.