회귀분석을 공부하게 되면
책이나 인터넷의 포스팅된 글에서 모델적합성의 중요성을 부각시키는 아래의
데이터 시각화 예제를 많이 보았을 것이다.
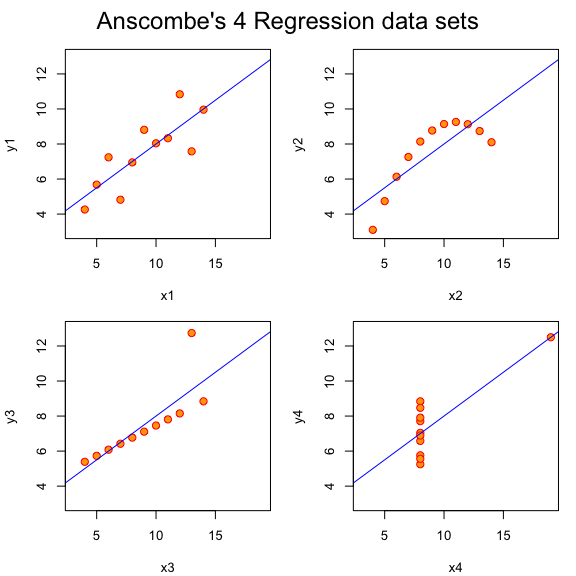
위 그림은 4개의 데이터의 패턴이 각기 다름에도 불구하고 단순회귀적합시
모두 동일한 모델을 만듦으로써 일어날 수 있는 오류를 우리에게
상기시킨다.
데이터시각화의 중요성을 부각시키는 예제로도 자주 활용되는데 그만큼
눈으로 직접 보는것이 힘이다.
나는 종종 이 예제를 활용하고 싶을때가 많았는데
이 데이터셋을 구하기 전 처음에는 데이터셋의 이름을 모르고 있어서
직접 눈대중으로 만들려는 멍청한 짓을 한적이 있었다.1
하지만 위에 사용된 데이터셋 이름이 Anscombe’s quartet 임을 알고는 구글링을 통해 손쉽게 얻을 수 있었다.
그런데 또 뒤늦게 알아 챈 것이 있는데
R에서 Anscombe’s
quartet 데이터셋이 빌트인 되어 있었다는 것이다.
데이터셋을 호출하기 위해선 anscombe 만 치면 되었구나…
anscombe## x1 x2 x3 x4 y1 y2 y3 y4
## 1 10 10 10 8 8.04 9.14 7.46 6.58
## 2 8 8 8 8 6.95 8.14 6.77 5.76
## 3 13 13 13 8 7.58 8.74 12.74 7.71
## 4 9 9 9 8 8.81 8.77 7.11 8.84
## 5 11 11 11 8 8.33 9.26 7.81 8.47
## 6 14 14 14 8 9.96 8.10 8.84 7.04
## 7 6 6 6 8 7.24 6.13 6.08 5.25
## 8 4 4 4 19 4.26 3.10 5.39 12.50
## 9 12 12 12 8 10.84 9.13 8.15 5.56
## 10 7 7 7 8 4.82 7.26 6.42 7.91
## 11 5 5 5 8 5.68 4.74 5.73 6.89으악. 많이 허무했다..
?anscombe 를 하고 나서 예제코드가 잘 준비된 것을 보니
지금까지 과정들이 헛수고임을 깨닫게 되었다.
그 충격에 이렇게 글로 포스팅을 하게 되었다.
이 멍청한 짓 마저 의외로 엄청 어려워 실패 😓↩︎