필자는 TensorFlow 를 활용한 딥러닝 구현은 아직까지도 직접 해본적이
없었는데
Keras 가 나오고서야 딥러닝을 처음으로 직접 시도해보게 되었다.
Keras 를 이용해 보고싶어 튜토리얼을 빠르게
훝어본적이 있었는데
그 과정을 정리한 글이다.
본글은 R에서 Keras 튜토리얼 예제를 따라해 본 것을 빠르게 정리한
글이며
딥러닝의 Hello world 격인 MNIST 의 숫자를 예측하는 모델을 만드는 것을
목적으로 한다.
딥러닝에 대한 이론적인 설명, 기술은 자세히 하지 않는다.
Keras 를 R에서 설치하기
R session 에서 다음 코드를 통해 설치가 가능하다.
devtools::install_github("rstudio/keras")
library(keras)
install_keras()Keras 를 설치하기 위해서 rstudio 배포판 keras package 를
설치한다.
이후 keras package 를 로드하고 install_keras() 함수를 통해
실제로 Keras 라이브러리를 설치할 수 있다.
라이브러리를 추가로 설치하라는 요구사항이 뜨면서 설치가 중단될 경우
(본인의 경우 python-virtualenv 가 없어서 중단됨)
Error: Prerequisites for installing TensorFlow not available.
Execute the following at a terminal to install the prerequisites:
$ sudo apt-get install python-virtualenv안내 받는
$ sudo apt-get install python-virtualenv등을 실행시켜 요구사항을 충족시킨 후 install_keras() 를
실행해 설치를 진행하면 되겠다.
MNIST 튜토리얼 예제 수행
지도학습의 대표적인 MNIST 예제를 수행해봄으로써 Keras 의 설치가 정상적으로 되었는지, 동작은 제대로 하는지 확인해보면 좋겠다.
Keras 를 쓰기전에 코딩과정은 보통 아래의 레파토리를 거치며 진행된다.

진행할 튜토리얼도
- 모델 정의
- 모델 형태 사전설정
- 모델 적합
- 모델 평가
- 모델을 통한 예측
이 과정이 모두 담겨있다고 볼 수 있다.
튜토리얼을 시작해보자.
우선 MNIST 데이터셋을 준비한다.
mnist <- dataset_mnist()
x_train <- mnist$train$x
y_train <- mnist$train$y
x_test <- mnist$test$x
y_test <- mnist$test$y
# reshape
x_train <- array_reshape(x_train, c(nrow(x_train), 784))
x_test <- array_reshape(x_test, c(nrow(x_test), 784))
# rescale
x_train <- x_train / 255
x_test <- x_test / 255위의 코드는 MNIST 의 숫자 사진들을 학습셋과 테스트셋으로 나누고 각각 라벨링을 정리한 것으로 보면 되겠다.
y_train <- to_categorical(y_train, 10)
y_test <- to_categorical(y_test, 10)타겟라벨링 y 경우 맨 처음에는 각각의 그림이 무슨 숫자인지를
벡터형으로 관리했는데 더미화(One-hot encode) 하여야 한다.
to_categorical() 함수를 통해 10개의 카테고리로써 One-hot
encoding 을 간편히 수행할 수 있다.
model <- keras_model_sequential()
model %>%
layer_dense(units = 256, activation = 'relu', input_shape = c(784)) %>%
layer_dropout(rate = 0.4) %>%
layer_dense(units = 128, activation = 'relu') %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 10, activation = 'softmax')모델링을 수행하기 전 모델링 방법과 레이어 구성 등의 Rule 을 적용하는
단계이다.
keras_model_sequential() 로 모델의 레이어를 구성하기 위한
초기 뼈대를 만들어 놓고 그 객체를 model 이 가져갔다면
layer_dense() 함수와 layer_dropout() 등의
함수들로 레이어의 순서와 구성을 기획할 수 있다.
단 layer_dense(), layer_dropout(),
layer_activation(), layer_masking() 등의
함수들을 거친 keras.models.Sequential 클래스 객체는 따로 할당연산자
없이도 레이어 구성이 바로 적용되는것이 (나에게 있어선) 독특했다.1
레이어 구성이 어떻게 되었는지 확인해 보고 싶다면
summary(model) 을 실행해 보자.
summary(model)## ___________________________________________________________________________
## Layer (type) Output Shape Param #
## ===========================================================================
## dense_7 (Dense) (None, 256) 200960
## ___________________________________________________________________________
## dropout_5 (Dropout) (None, 256) 0
## ___________________________________________________________________________
## dense_8 (Dense) (None, 128) 32896
## ___________________________________________________________________________
## dropout_6 (Dropout) (None, 128) 0
## ___________________________________________________________________________
## dense_9 (Dense) (None, 10) 1290
## ===========================================================================
## Total params: 235,146
## Trainable params: 235,146
## Non-trainable params: 0
## ___________________________________________________________________________다음으로 compile() 함수를 통해 비용함수와 최적화 방법,
최적화 평가기준을 설정할 수 있다.
튜토리얼 코드상에선 아래의 방법으로 설정했는데 그외 다양한 방법이 있는지
살펴보기 위해서 compile() 함수의 도움말을 살펴보았지만 큰
도움이 안되어서 당황스러웠다.
이때 부터는 Keras document 를 직접 훝어보아야 할듯 하다.
model %>% compile(
loss = "categorical_crossentropy",
optimizer = optimizer_rmsprop(),
metrics = c("accuracy")
)본격적으로 학습 및 평가를 해보자.
학습은 fit() 함수를 통해 가능하며 8 epochs 과 128 의
batch 사이즈로 학습을 수행하는 코드이다.
history <- model %>% fit(
x_train, y_train,
epochs = 8, batch_size = 128,
validation_split = 0.2
)loss 가 계속 줄어드면서 학습 및 최적화를 하는 과정이 8 epochs 만큼
진행 되는 로그가 출력될 것이다.
약 1분이 지나면 코드수행이 끝나게 되고 history 객체를 통해
학습수행과정에 대한 정보를 확인할 수 있다.
plotting 을 하면 학습과정중 training set 과 validation set 기준으로
정확도와 loss 가 epoch 별로 어떻게 변화했는지를 볼 수 있다.
plot(history)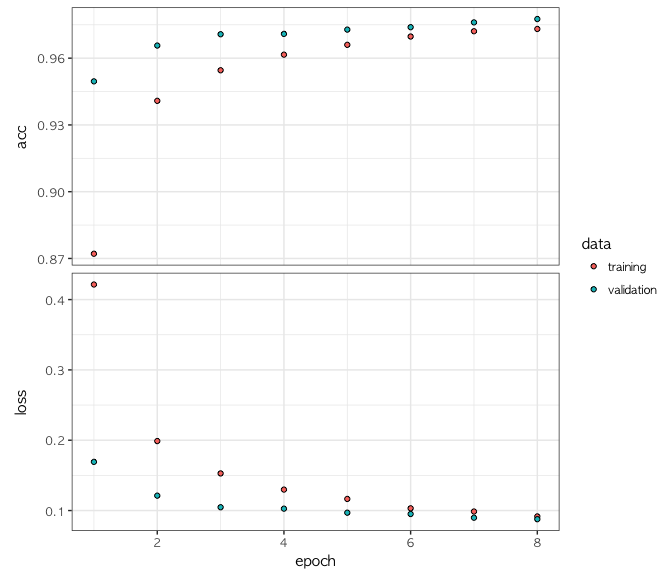
Keras 를 이용한 학습 모델이 테스트셋을 기준으로 얼마만큼 예측성능률을
가지고 잇는지 평가해 보자.
평가는 evaluate() 함수를 이용한다.
model %>% evaluate(x_test, y_test)## $loss
## [1] 0.08196825
##
## $acc
## [1] 0.9788테스트셋에 대한 예측정확도가 97.88% 가 나온것을 볼 수 있다.
실제로 Testset 을 모델에 입력하여 어떤 숫자를 예측하는지 보고 싶다면
model %>% predict_classes(x_test[1:10, ])## [1] 7 2 1 0 4 1 4 9 5 9를 통해 뽑을 수 있겠다.
Reference
물론 다른 이름의 객체로 할당시키는것도 가능했다↩︎