목표
크롤링과 같은 실전은 경험이 전무하였는데, 지인의 질문 덕분에 제대로
된 크롤링 경험을 쌓을 수 있었다.
대단한 경험은 아니지만 나에게 있어 신선했던 경험을 공유하기 위해 정리해
본다.
본 포스팅 글은 특정 웹페이지의 이미지 파일들을 내 컴퓨터 하드로
저장시키기 위한 R 코드를 작성하는것을 목표로 한다.
이 목표를 이룰 수 있는 완벽한 방법을 소개하는 것은 아니지만, 최소한 http
프로토콜을 통해 접근가능한 이미지는 자동으로 다운로드할 수 있는 방법이
될 것이다.
웹페이지의 그림파일들을 저장시키고 싶은데 그러기엔 많은 이미지 파일들이
있어 손수 저장시키기엔 부담이 있을 경우 대안이 될 수 있겠다.
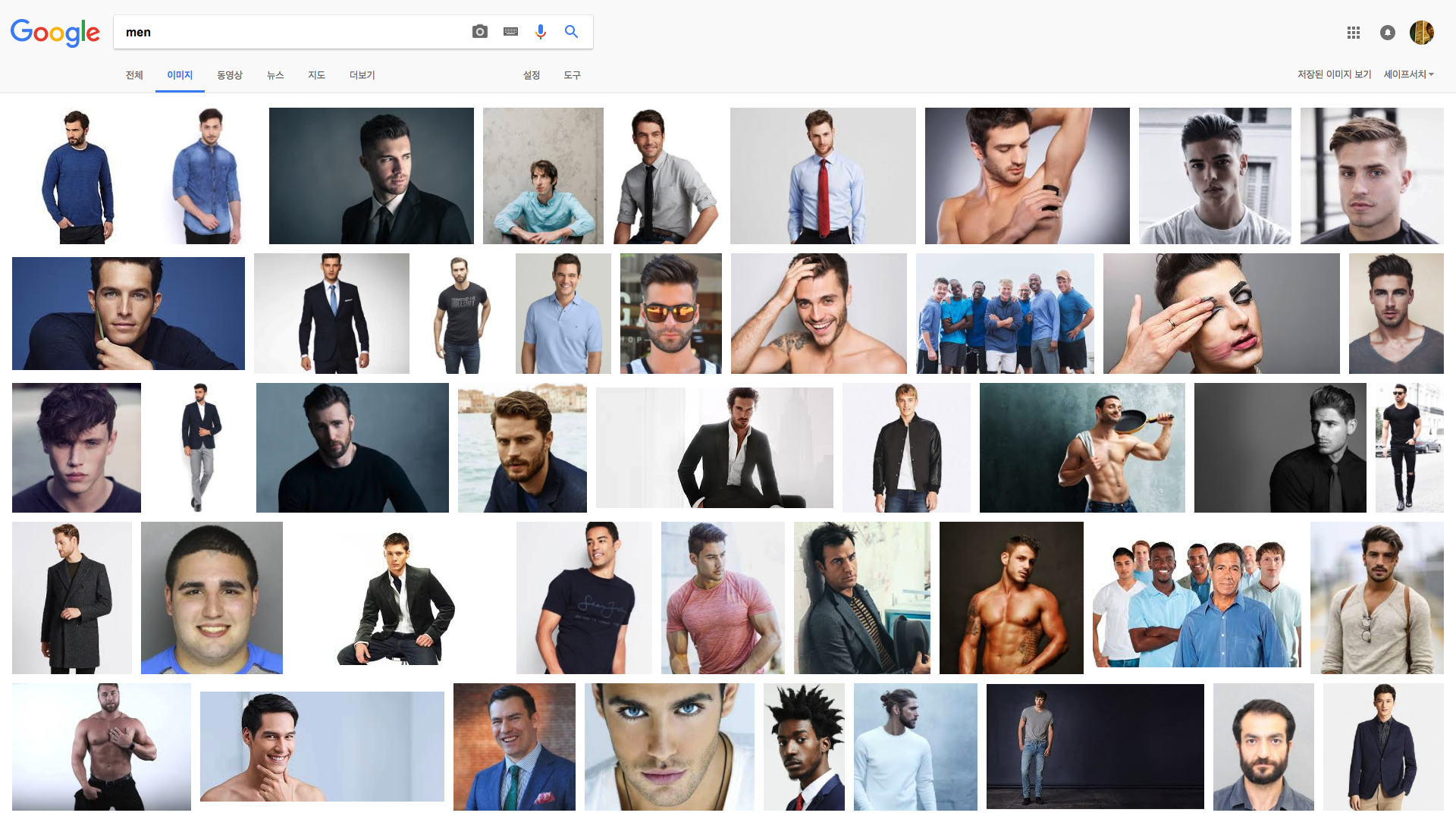
예제로 선택한 웹 사이트는 Google 의 이미지 검색에서 “men” 이런 검색어로 검색시 나타나는 웹페이지로 아래 링크와 같다.
준비
우선 이미지 파일만을 크롤링 하는 방법에 대해서 구상할 필요가
있다.
크롤링 컨셉은 이렇게 잡았보았다.
- 첫번째 : 웹페이지의 HTML 코드를 파싱하여 R 에서 가공할 수 있는
형태로 변환한다.
- 두번째 : 변환된 HTML 코드에서 <img> tag 의 src 인자값을
정규표현식을 이용해 추출한다.
- 세번째 : 준비된 src 인자값 링크들을 R 객체로 만들고 download 명령을 반복문을 이용해 내려준다.
이렇게 되면 자동적으로 이미지 파일들을 선별하여 내 컴퓨터로 가져올 수 있게 될 것이다.
패키지는 아래의 3개 패키지를 이용하여 코딩을 하였다.
library(RCurl)
library(XML)
library(dplyr) # Optional package (for pipe operator)시작
img tag 의 src 인자값 크롤링
R 에서 “men” 이란 이미지검색 웹 사이트의 html code 를 character 형식으로 가공하기 위해선 아래의 절차가 필요했다.
htmlcode <- getURL("https://www.google.co.kr/search?biw=1436&bih=782&tbm=isch&sa=1&q=men&oq=men&gs_l=img.3...4008.4572.0.5170.0.0.0.0.0.0.0.0..0.0....0...1c.1.64.img..0.0.0.id2CbaNm_HQ") %>%
htmlParse %>%
capture.outputgetURL() 함수는 RCurl package 의 함수이다.
함수에 url 을 입력하는 형태로 사용하며, 웹피이지의 html 코드를 그대로
가져오는 역할을 한다.
단 단락이 나뉘어 있지 않은, 이쁘지 않은 형태 그대로 가져오기 때문에
추후에 정규표현식을 이용한 패턴추출시 어려운 점이 생긴다.
htmlParse() 함수는 XML package 의 함수인데 html 의
구문을 어느정도 이해한 후 단락을 나눠주는 역할을 한다.
단 이 함수를 통해 반환되는 결과물은 class 가 특이한 형태로
반환된다.
우리는 대단한 것을 하지 않을 것이므로 일반적인 character 형태로 다시
되돌리기 위해 capture.output() 함수를 한번 더 거친 결과물을
htmlcode 객체로 할당했다.
htmlcode 의 head 부분만 살펴보면 html 의 시작을 알리는
“<!DOCTYPE html>” 이 첫번째 단락에 있는것을 볼 수 있다.
head(htmlcode)## [1] "<!DOCTYPE html>"
## [2] "<html itemscope=\"\" itemtype=\"http://schema.org/SearchResultsPage\" lang=\"ko\">"
## [3] "<head>"
## [4] "<meta content=\"text/html; charset=UTF-8\" http-equiv=\"Content-Type\">"
## [5] "<meta content=\"/images/branding/googleg/1x/googleg_standard_color_128dp.png\" itemprop=\"image\">"
## [6] "<link href=\"/images/branding/product/ico/googleg_lodp.ico\" rel=\"shortcut icon\">"R에서 접근 가능한 html code 가 준비 되었으므로 이젠 정규표현식을 통해 우리가 필요로하는 이미지 주소링크를 추출한다.
Step1) 우선 img 테그 전체를 소비
img_tag_pattern <- "<img.*?>"
img_tag <- htmlcode %>% regmatches(regexpr(img_tag_pattern, .))Step2) 소비된 img tag 중에서 src argument 값을 소비
src_href_pattern <- "(?<=src=\\\").*?(?=\\\")"
src_href <- img_tag %>% regmatches(regexpr(src_href_pattern, ., perl=T))각각의 정규표현식을 설명하면 첫번째 단계의
<img.*?> 은 img tag 전체를 선택하는 패턴이며,
두번째 단계의 (?<=src=\\\").*?(?=\\\") 는 src 인자값을
선택하되 양옆의 “” 큰따옴표는 소비하지 않는 패턴이다. (R의 grep 함수에서
정규표현식의 이스케이프가 제대로 동작하지 않는다면
perl=TRUE 를 통해 해결이 가능하기도 하다.)
단계를 크개 2개로 나누어 정규표현식을 짠 이유는 img tag 중에서 src 인자값을 추출하여야 이미지링크 문자열만 뽑을 수 있기 때문이다.
이렇게 준비된 결과 src_href 를 살펴보면 다음과 같다.
src_href## [1] "/textinputassistant/tia.png"
## [2] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSbLuxP_mV-2Blp3keuv1jLyR0VQ9ILVOgya0j7Ep-2Dksp4-BJUlUePKk"
## [3] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTrn3mRi5juK7hmG8QCt9g7gtrLBw4gUzKOj_h-mK-kshb4k25QJEGZPw"
## [4] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR6tMVawjxnYdeUzSvKQFP-KqBm8E-yyiTa5efDl2FEe4pesKdv7lfAzv3z"
## [5] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSZOQvXU6ril_HpFXgdmXkItM0gcJTw8M5nmKTfxA84AlR7PcD9LpTNLAk6"
## [6] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTaailzt78W3ZQh40T90r1Rka4_l_c5GJofA-cljDIemIJBGxoHOUlz-vA"
## [7] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR-aGhrwrnrr_YsTfRR50uNsiIv4K2IA51aTbCzq8VusdAZXNlSb5RKHy_R"
## [8] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRpiejaSKcbEH11PNhLNR2GvMvZwEwGtBUinztt-whzx4sR8lnUeJ_vaZk"
## [9] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTpBez4kk2CFHA3jpUPGP50CcSR6z5Fxkb9QFCdaNvMBulGm3fP8LwrQskT"
## [10] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQjzbgIw-ShArINy1_GDlGCcx0m32NT_Eutvk0C2UZv49AQlRr69SB5Jftx"
## [11] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRvhOMkCeW0EmtQ-AL-4a0kWl7ZXkqvCQ4Tj3ZOG4uZZQmPfvIEzqEFd4g"
## [12] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQvs5RWc9IkF20O_f9DV5jS52MyP8we-AQL04cYTFOCy1fP5AFp6jdsktGP"
## [13] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQE5VmDg31WM4R_LqLRNfTznNDjIgvI6EO7M6A5C-Jv6iN4ftytUjH1IUA"
## [14] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR6isRfLORS1SRnCbdvl6yZvWI2ZPC7Aqpo5AvkrJpw1WdHx76nMGr6MwSn"
## [15] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRVdiDyYMStHbeWrSmPhLXiWh2sVqtJ4y258ouj8AzprnTU3F3gBYhgDsOC"
## [16] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSUMmQHkie4oZXnRk152B1AmJsth3T-AUDe4MqLmxXyiWYc0rl120wq4Qw"
## [17] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQZAZ_Q0yHk-qSbTdVcNG1HD_UZAe4aDWIo2ceeVmAfVknINNnWayu7G8XD"
## [18] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRR1qjqFOSi51g7p0DXeSOckOlz_u2SZY9sahJoH6DNQ0P7vg3f2kGP0T_P"
## [19] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRT0jWP40pTHW6SXhs6-8xy_GbTZGAvzED35frFdvt30s0e4BO5C--lrHxL"
## [20] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSFZ2eXnttnQ7jfg-_0tYIpFcNgATWB0mWlVAFwCdtlnlZqay_egjua6Gfpdg"
## [21] "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSiO_WgfPqsK8XQNXEZ7F6zUHu9W9JiiArAdbGT-gLh4eQbumQEx5mSFJA"이 결과를 볼 때 추가적인 전처리가 더 필요할 수 있을거라
예상된다.
예를들어 “http:” 로 시작하는것만 소비해야 정상적인 이미지 파일
다운로드가 가능할 것이다.
첫번째 링크 /textinputassistant/tia.png 는 루트에서 직접적으로 가져오는
링크 이므로 우리가 접근할 수 있는 이미지가 아니다.
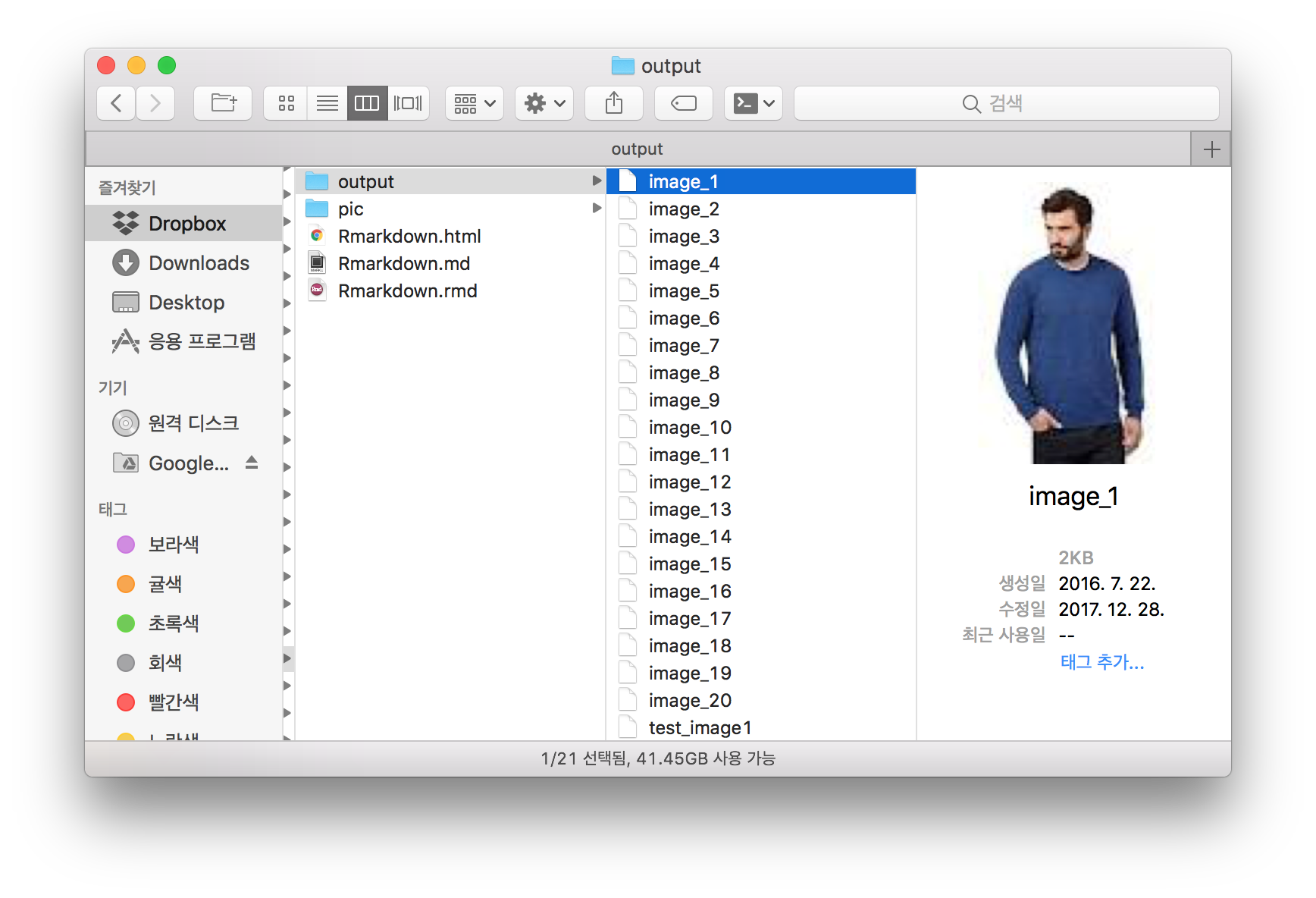
src_href <- src_href[-1]이미지 파일들 다운로드
이후의 예제는 20개의 준비된 이미지 파일링크를 반복문을 돌려 자신의
하드로 가져오는 코드이다.
우선 한개의 파일을 다운로드 하는방법부터 살펴보면
download.file(src_href[1], "output/test_image1")위의 코드는 첫번째 링크의 이미지파일을 워킹디릭토리의 output 폴더에
“test_image1” 라는 파일로 저장시키는 코드이다.
이를 이용해서 반복문을 통해 20개 모든 이미지를 다운로드하는 코드를
짜면
for(i in src_href %>% length %>% seq){
download.file(src_href[i], paste0("./output/image_", i))
}output 폴더에 “image_1”, … , “image_20” 개의 이미지가 잘 저장되어 있는지 확인해보면 되겠다.