데이터 프레임 형을 파일단위로 저장할 때 R에서는 다양한 방법들이
있다.
크게 유형 분류를 하면
- csv 와 같은 텍스트형으로 저장하는 방법
- 이진 형태, 즉 binary 파일로 저장하는 방법
으로 나눌 수 있는데
호환성을 위해선 1번 방법이 좋지만, 저장 및 로드하는 속도, 파일의 볼륨을
줄이기 위한 압축 부분을 포기해야 하고,
속도를 위해선 2번 방법이 좋지만 텍스트에디터 등으로 파일을 간편하게
확인하는 것을 포기해야 하는 등
유형별로 장단점이 있다.
본 글은 2번 이진 형태의 방법으로 R에서 데이터 프레임의 정보를 파일로 저장하는 방법 중 읽고 쓰는 속도가 상대적으로 빠른 편인 fst package 를 이용한 방법을 소개하고자 한다.
Benchmark
소개에 앞서 처리속도가 다른 방법에 비교해 얼마나 빠른지 결과를 먼저
확인 해 보고 싶었다.
아래 코드는 샘플 데이터프레임을 만든 다음
오늘 주제인 fst 형으로 저장하는 방법과 그 외의 방법들로 저장하는 코드별
코드수행 시간을 측정하여 plotting 해 보는 코드이다.
library(dplyr)
library(microbenchmark)
nr_of_rows <- 10^8
df <- data.frame(Logical = sample(c(T, F, NA), prob = c(.85, .1, .05), nr_of_rows, replace = T),
Integer = sample(1L:100L, nr_of_rows, replace = T),
Real = sample(sample(1:10000, 20) / 100, nr_of_rows, replace = T),
Factor = as.factor(sample(labels(UScitiesD), nr_of_rows, replace = T))) %>% tbl_df
df## # A tibble: 100,000,000 x 4
## Logical Integer Real Factor
## <lgl> <int> <dbl> <fct>
## 1 T 30 97.6 Chicago
## 2 T 42 61.0 Atlanta
## 3 NA 21 97.6 Chicago
## 4 T 3 97.6 Miami
## 5 T 89 48.2 Washington.DC
## 6 T 52 62.9 SanFrancisco
## 7 T 41 31.5 NewYork
## 8 T 38 47.1 Chicago
## 9 T 21 48.2 Denver
## 10 T 78 48.2 Denver
## # ... with 99,999,990 more rows저장대상으로 테스트에 쓸 데이터프레임 df 를 만들어
보았다.
1억건의 레코드를 가진 데이터프레임이다.
이 df 를
write.tabledata.table::fwritesaveRDSfeather::write_featherfst::write_fst
의 5개 방법별로 저장하는 시간을 반복측정하는 것을 microbenchmark package 의 도움을 받아 실행해 본다.
bench <- microbenchmark(write.table = write.table(df, file = "output/df_writetable.csv", quote = F, row.names = F, sep = ","),
fwrite = fwrite(df, file = "output/df_fwrite.csv"),
saveRDS = saveRDS(df, file = "output/df_saveRDS.rds"),
write_feather = write_feather(df, path = "output/df_feather.fea"),
write_fst = write_fst(df, path = "output/df_fst.fst"), times = 10)autoplot(bench)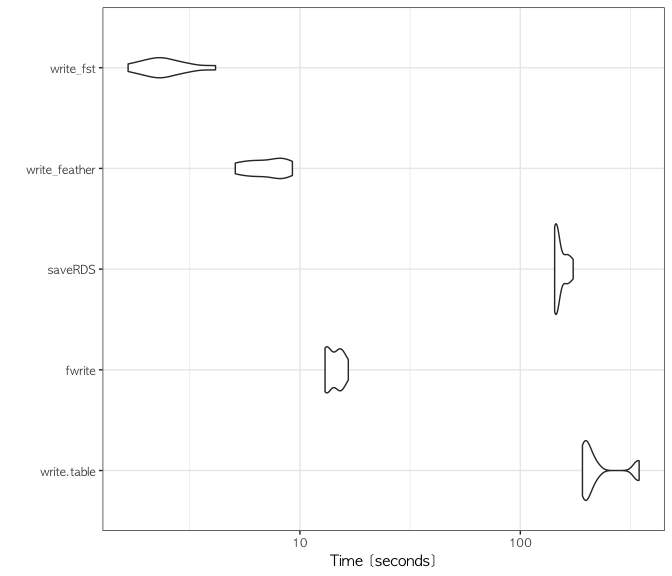
fst 형으로 저장하는 방법이 약 2.52초로 다른 방법들에 비해 비약적으로 빠른 것을 볼 수 있다.
쓰기 속도 외에도 읽기 속도 역시 좋은 성능을 보인다.
읽기 테스트는 생략하지만 fst package 홈페이지에 지금까지의 벤치마킹과 비슷한 실험 결과물이 소개되었으니 참고해 보면 좋겠다.
사용법
벤치마킹 테스트 코드에 fst 형으로 저장하는 방법에 대한 코드가 있었다. 바로 이 부분인데
write_fst(df, path = "output/df_fst.fst")저장시킬 데이터프레임 객체명, 저장시킬 파일경로를 지정 이 두 가지가 필수이다.
data <- read_fst("output/df_fst.fst")읽는 방법은 read_fst() 함수안에 이전에 저장시킨
파일경로를 지정하고 할당하는 방식이다.
특징
fst package 는 여러 특징이 있는데 가장 눈에 띄는 특징은
자동적으로 병렬스레드를 이용하여 저장 및 읽는 처리속도의 효율을 높인다는
것이다.
볼륨이 큰 데이터프레임을 write_fst() 함수로 저장하곤 할 때
이러한 로그가 나타나는 것을 보면 알 수 있다.
write_fst(df, path = "output/df_fst.fst")Written 9.6% of 100000000 rows in 2 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 18 secs.
Written 15.8% of 100000000 rows in 3 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 15 secs.
Written 22.5% of 100000000 rows in 4 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 13 secs.
Written 28.7% of 100000000 rows in 5 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 12 secs.
Written 33.7% of 100000000 rows in 6 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 11 secs.
Written 40.4% of 100000000 rows in 7 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 10 secs.
Written 46.6% of 100000000 rows in 8 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 9 secs.
Written 51.6% of 100000000 rows in 9 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 8 secs.
Written 57.2% of 100000000 rows in 10 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 7 secs.
Written 62.8% of 100000000 rows in 11 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 6 secs.
Written 67.8% of 100000000 rows in 12 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 5 secs.
Written 72.8% of 100000000 rows in 13 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 4 secs.
Written 77.9% of 100000000 rows in 14 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 3 secs.
Written 82.9% of 100000000 rows in 15 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 3 secs.
Written 88.5% of 100000000 rows in 16 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 2 secs.
Written 93.5% of 100000000 rows in 17 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 1 secs.
Written 97.4% of 100000000 rows in 18 secs using 4 threads. anyBufferGrown=no; maxBuffUsed=37%. Finished in 0 secs. data.table package 의 fwrite(), fread()
에서도 가지고 있는 기능이지만 fst package가 조금 더 높은 성능을 보이기도
한다.
{kind=link}
압축저장도 지원한다.
write_fst() 함수의 인자들을 살펴보면 compress
인자가 있고 기본적으로 50인데 이를 조정하여 압축률을 높이거나 낮출 수
있다.
write_fst(df, path = "output/compress_1.fst", compress = 1)
write_fst(df, path = "output/compress_50.fst", compress = 50)
write_fst(df, path = "output/compress_100.fst", compress = 100)system("ls -lh output/compress*")-rw-r--r--@ 1 lovetoken staff 1.2G Mar 1 10:21 output/compress_1.fst
-rw-r--r--@ 1 lovetoken staff 247M Mar 1 10:22 output/compress_100.fst
-rw-r--r--@ 1 lovetoken staff 582M Mar 1 10:21 output/compress_50.fst압축률을 1로 한 것과 100으로 한 것 간의 파일 용량이 각각 1.2Gb, 247Mb 으로 차이가 큰 것을 볼 수 있다.
마지막으로..
fst package 가 혹 save(), saveRDS() 처럼 R
객체를 저장할 수 있다고 생각하면 안 된다.
서두에도 말했듯이 데이터프레임 형 객체만 저장할 수 있다.
데이터프레임 형을 저장하는데 특화된 것이 특징이라면 특징이겠다.